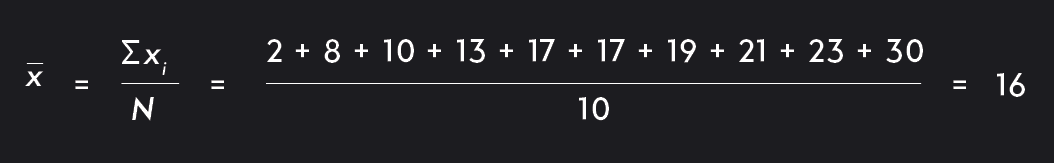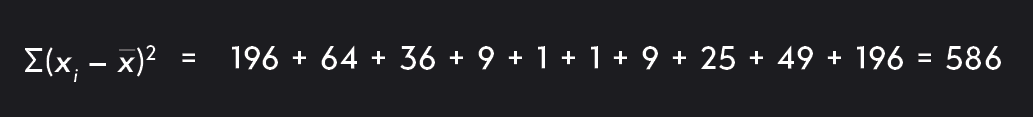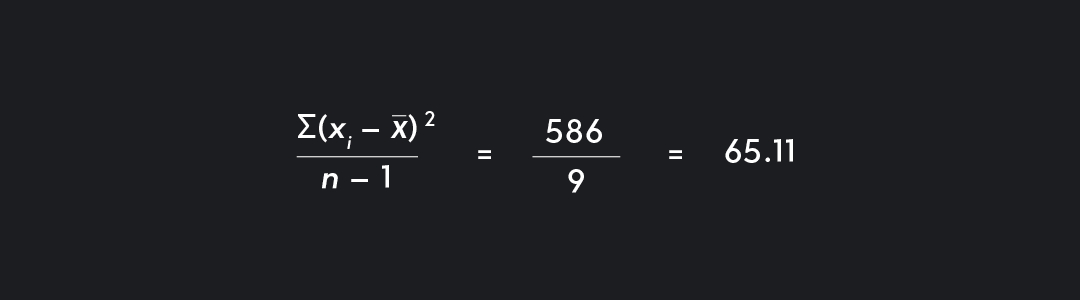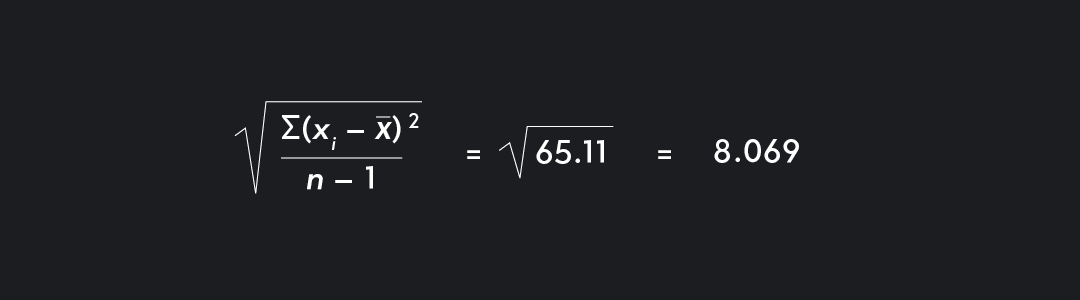A Step-by-Step Guide on How to Calculate Standard Deviation
10.06.2021 • 12 min read
Sarah Thomas
Subject Matter Expert
Standard deviation is one of the most crucial concepts in the field of Statistics. Here, we'll take you through its definition and uses, and then teach you step by step how to calculate it for any data set.
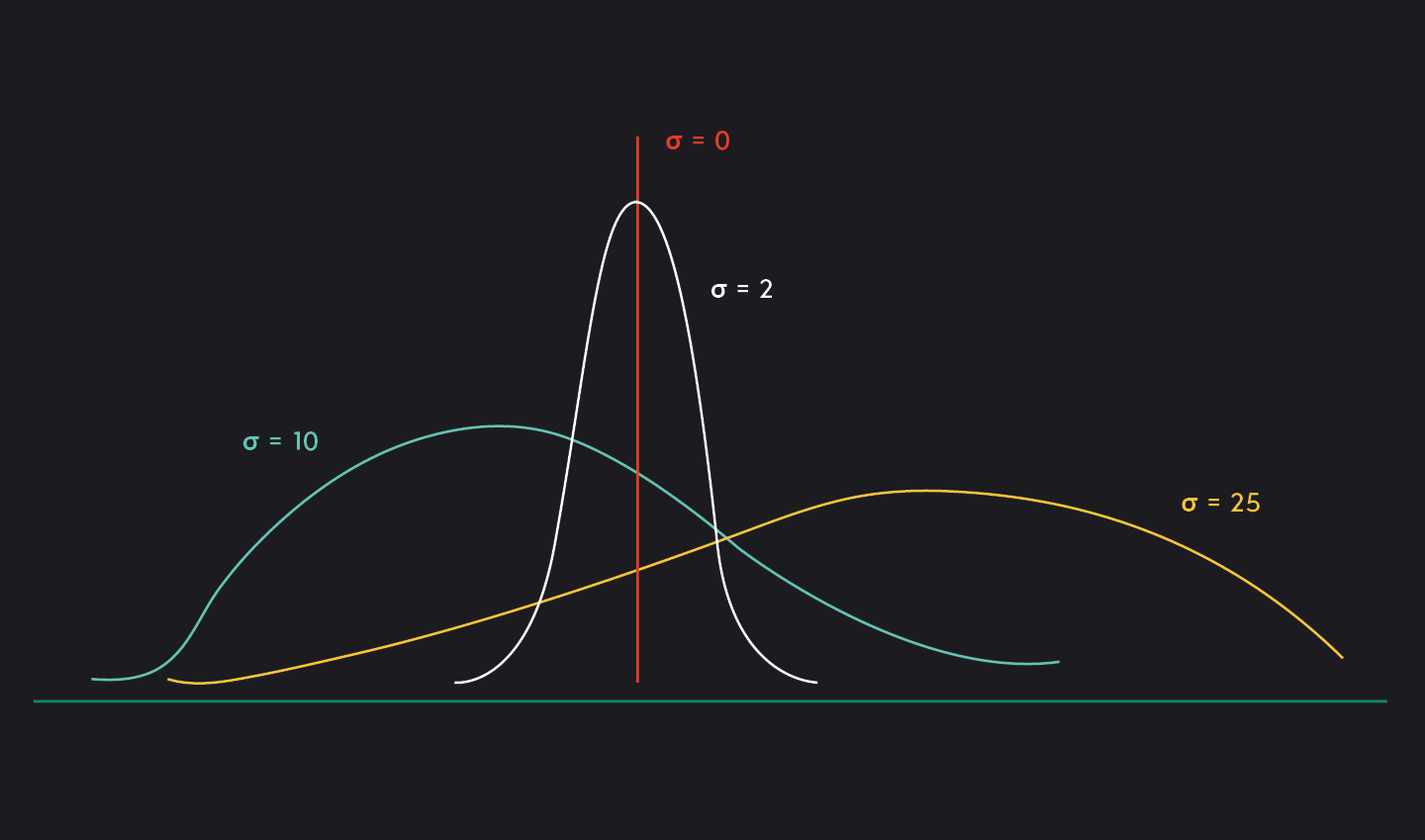
Standard deviation (σ or s) is a parameter or statistic that measures the spread of data relative to its mean. It is always positive or zero. A large standard deviation indicates that the data are widely spread out around the mean, while a smaller standard deviation indicates that the data are more tightly clustered around the mean. A standard deviation of zero only occurs when all values in the data are of equal value, and hence, there is no variation in the data.
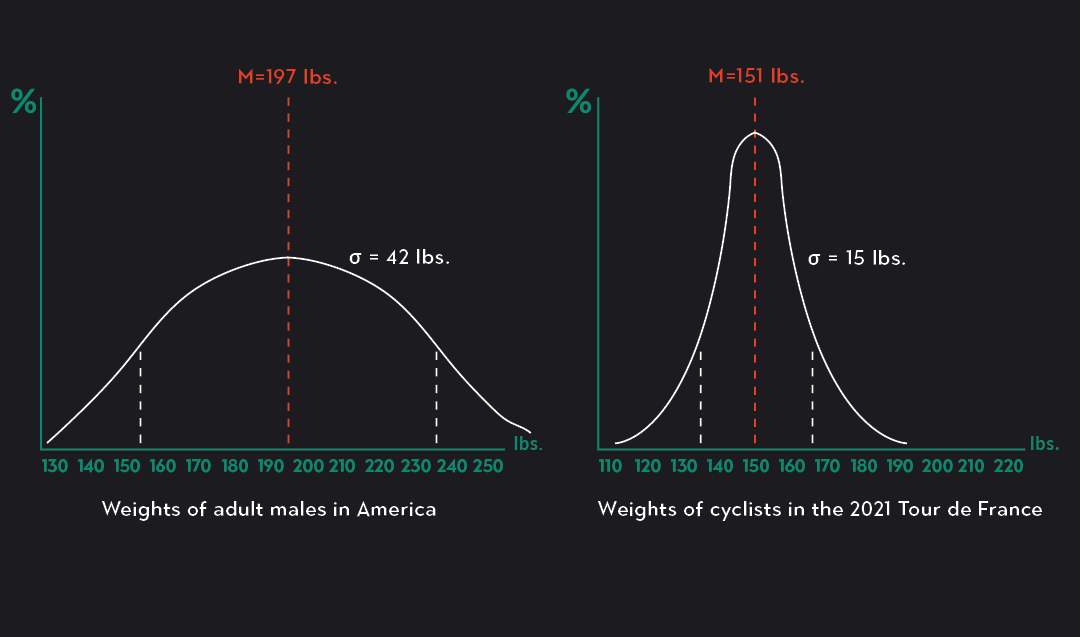
As a quick example, let’s look at two sets of data represented in the graphs below. The chart on the left shows the distribution of weights for adult males in America (aged 20 and above). The mean weight is 197 pounds, and the standard deviation is 42 pounds. The weights vary widely depending on factors such as age, height, fitness, and diet.
In contrast, the graph on the right shows the distribution of weights for participants in the 2021 Tour de France (the Tour de France is a world-famous annual cycling event for professional male cyclists). Here, the mean weight is 151 lbs, and the standard deviation is 15 pounds. The difference in the mean and standard deviation between the two groups makes sense if you think about it. Cyclists tend to be lean (a lot thinner than the average American male), and they tend to be of similar stature to one another. There is less variation in the weights of professional cyclists than there is in the weights of the entire adult male population in the United States. The smaller standard deviation (15 pounds rather than 42 pounds) reflects this.
A Note on Notation
The standard deviation for a population is often denoted by the Greek letter sigma, σ. When calculated for a sample, the standard deviation is often denoted by the lower-case letter, s. You may also see standard deviation abbreviated as SD or STDEV.
How Many Standard Deviations Away?
The standard deviation tells us, on average, how far away a single data point is from the mean, but any particular observation in your data may be more or less than one standard deviation away from the mean. We can describe the distance between any point in a data set and the data set’s mean in terms of standard deviation units.
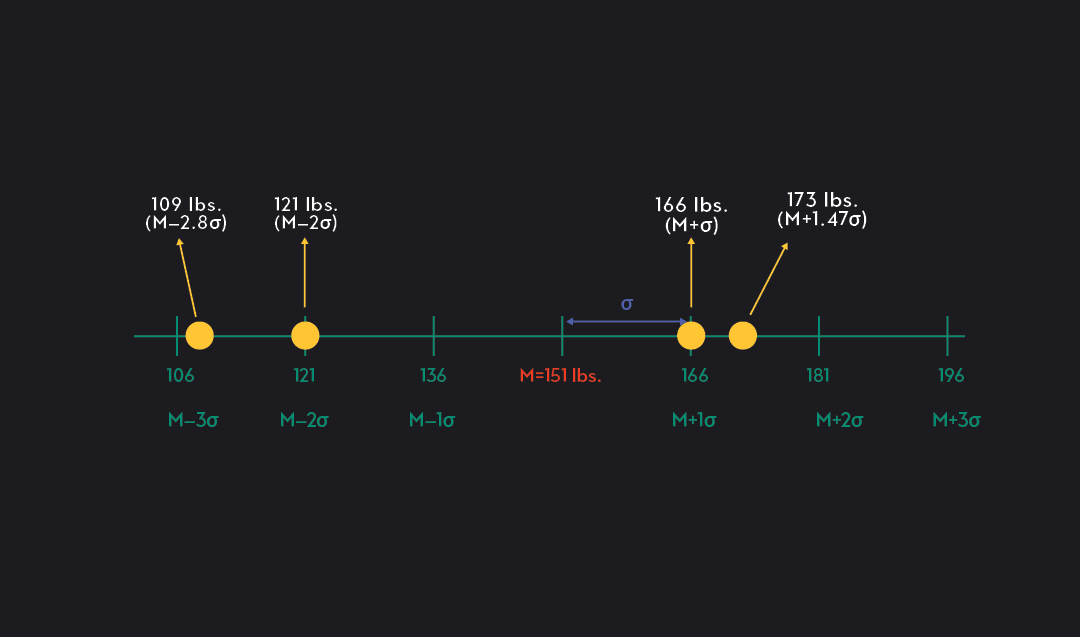
In the case of the Tour de France cyclists, the mean was 151 lbs, and the standard deviation was 15 lbs. Any particular cyclist’s weight, however, can be described in standard deviation units as follows:
A cyclist weighing 166 lbs has a weight that is one standard deviation (1σ) above the mean (166 = 155 + 15)
A cyclist weighing 121 lbs has a weight that is 2σbelow the mean (121 = 151 - (2)(15))
A cyclist weighing 173 lbs has a weight that is 1.47σabove the mean (173 = 151 + (1.47)(15))
A cyclist weighing 109 lbs has a weight that is 2.8σbelow the mean (109 = 151 - (2.8)(15))
And so on.
Why Is Standard Deviation Important?
Standard deviation is a useful measure in that it tells you right away whether data are widely dispersed or tightly clustered around the mean. As you have just seen, the standard deviation also provides an easy way to describe the distance between any particular point in the data and the mean of the data.
For most data sets, the majority of observations will fall within one standard deviation of the mean. As a rule of thumb, observations that lie more than two standard deviations away from the mean are considered "far" from the mean. Knowing this allows statisticians to understand their data better. For example, if someone told you that German cyclist Max Walscheid weighs 202 lbs, you might not have a good sense of how his weight compares to other cyclists unless you know a lot about cycling. However, knowing that his weight is 3.4σ above the mean gives you an immediate understanding that Walscheid’s weight is far above the average weight of his competitors. He is an outlier.
Standard Deviation and the Empirical Rule (68-95-99.7)
Standard deviations are particularly useful when it comes to describing data that are normally distributed. A normal distribution, if you are not already familiar, is a bell-shaped distribution that is unimodal and symmetric about the mean. Because the Normal distribution is symmetric about the mean, we can make precise statements about the proportion of observations that lie within certain segments of the distribution. We do this using the empirical rule.
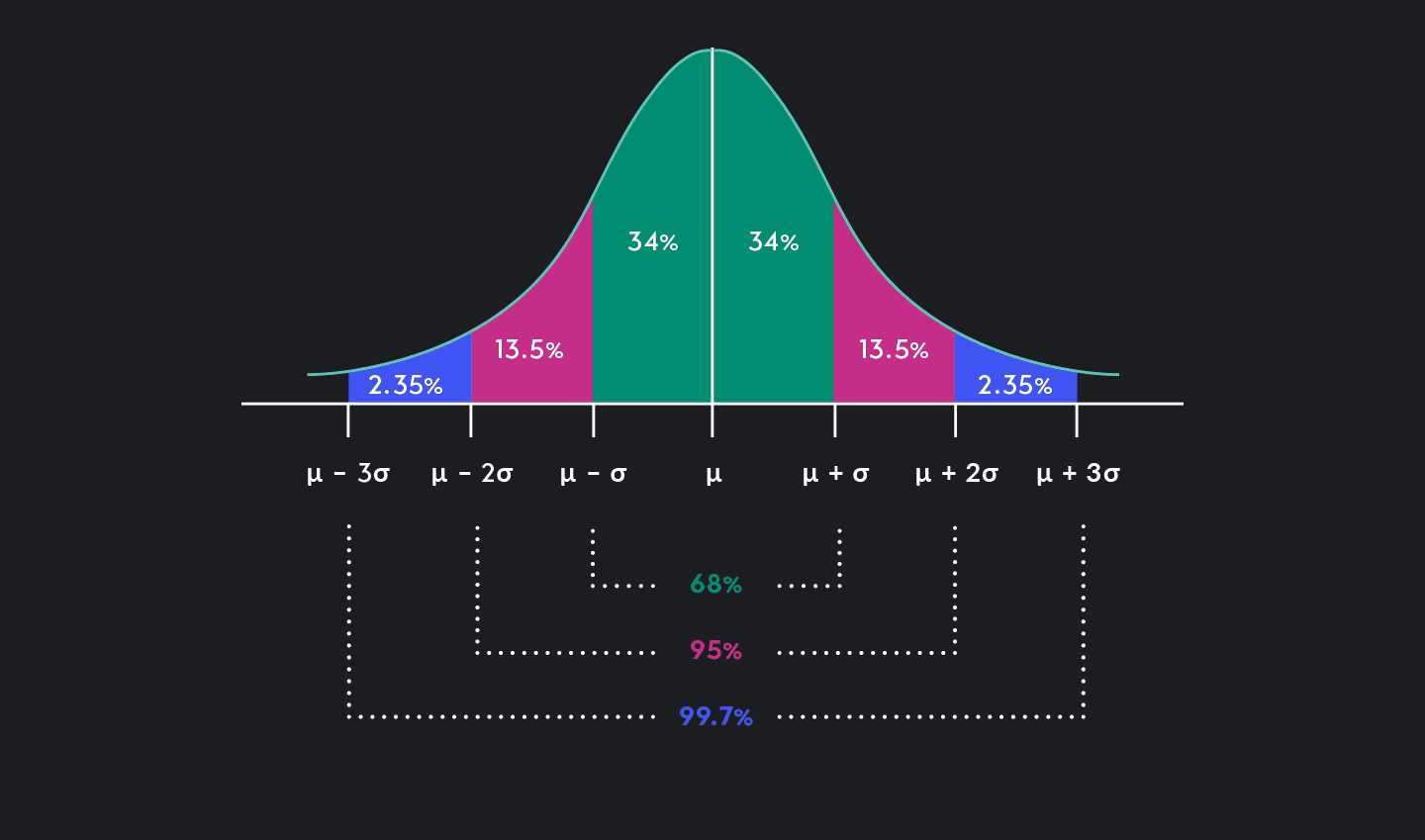
The empirical rule (or the 68-95-99.7 rule) states that:
68% of all observations in a normal distribution lie within one standard deviation of the mean (μ ± σ)
95% of all observations lie within two standard deviations of the mean (μ ± 2σ)
And 99.7% of all observations lie within three standard deviations of the mean (μ ± 3σ)
In other words, most observations in a normal distribution lie within one standard deviation of the mean, and hardly any of the observations lie beyond three standard deviations of the mean. Observations that are further than ±3σ are just 0.3% of the observations (100% - 99.7%).
The empirical rule can be applied even when data is approximately normal. Because a normal distribution can approximate so many different types of data, the empirical rule comes in quite handy!
Using the empirical rule, we know that 68% of observations in a Normal distribution lie within 1σ of the mean, 95% of observations are within 2σ of the mean, and 99.7% of observations are within 3σ of the mean.
Because a Normal distribution is symmetric about the mean, we can further divide the areas under a Normal distribution to find probabilities for smaller segments of the distribution (see the figure below). For example, we can further state that 34% of observations are between the mean and one standard deviation above the mean, or that just 2.35% of data are between (μ - 3σ) and (μ - 2σ).
How to Calculate Standard Deviation
The formulas for calculating standard deviation are below. The formula on the left is the formula for the population standard deviation sigma,σ, and the formula on the right is for the sample standard deviation, s.
Notice that the calculations are essentially the same. The only real difference is in the denominator. For the population parameter, σ, you divide by the population size, N, and for the sample statistic, s, you divide by the sample size minus one (n-1).
These formulae may look messy, but if you look closely, ignoring for a moment the square root sign, you’ll notice that what you are essentially calculating is an average of the squared distances between each data point and the mean of the data ((xi−μ)2 in the case of the population and ((xi−xˉ)2 in the case of the sample).
The Σ symbol, if you are not familiar, is a summation sign. It means “take the sum of,” so you are summing up all of the squared distances between the data points and the mean and dividing by the total number of data points N (or the total number of data points minus one in the case of the sample standard deviation). We'll explain why we first square and then take the square root of these distances later in this article.
σ=N∑(xi−μ)2 or s=n−1∑(xi−xˉ)2
A chart comparing Population Standard Deviation with Sample Standard Deviation
Steps for Calculating Standard Deviation
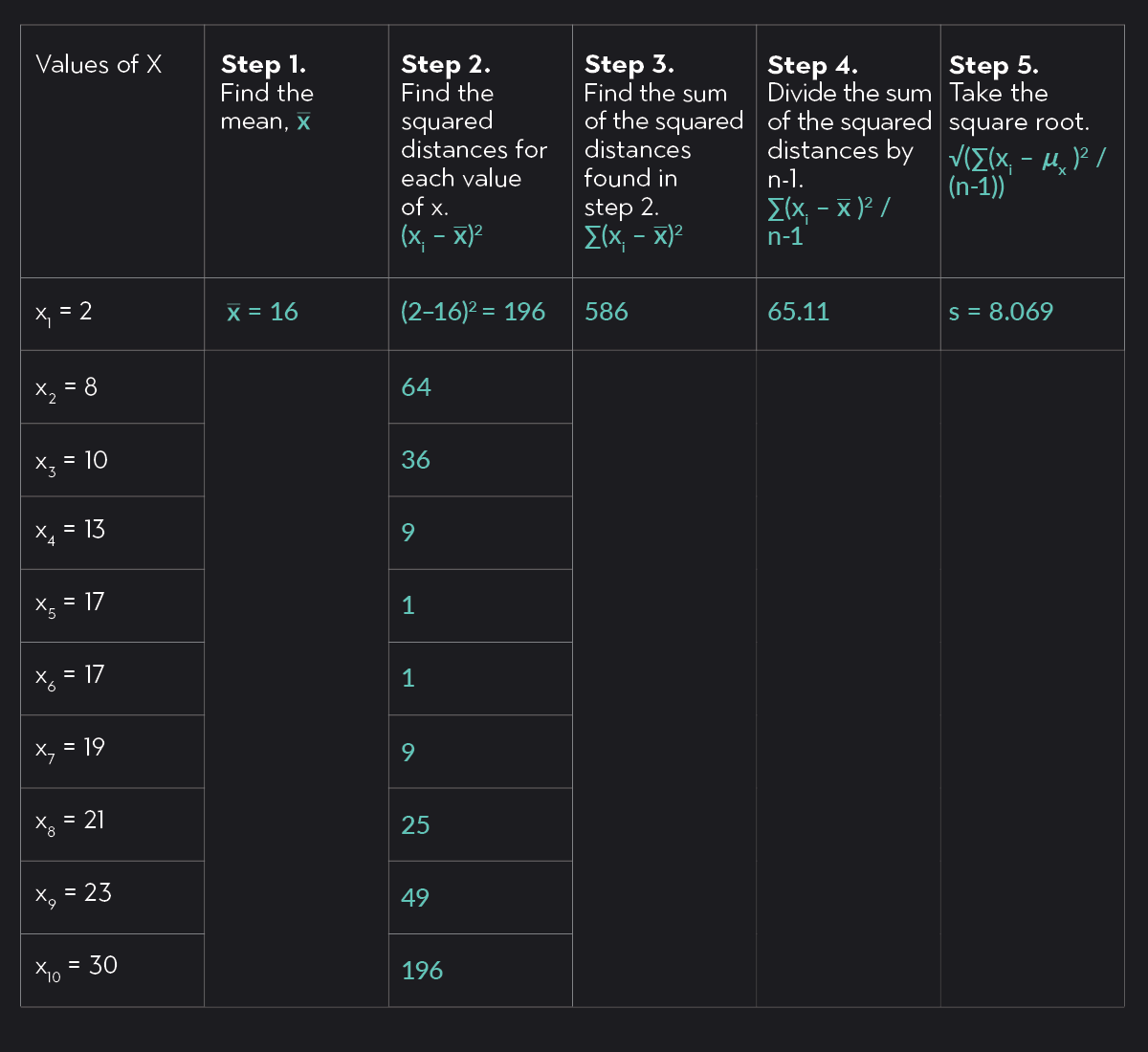
Below is a step-by-step example of how to calculate a standard deviation. To keep things simple, we’ll use a sample with just 10 data points (n=10).
X = {2, 8, 10, 13, 17, 17, 19, 21, 23, 30}
The steps for calculating the standard deviation are listed below, and they are also shown in the following table.
Step 1. Calculate the mean of your data, xˉ.
Step 2. Find the squared distances between each data point and the mean.
Step 3. Sum up all of the squared distances from Step 2, Σ(xi−xˉ)2.
Step 4. Divide the sum from Step 3 by the sample size, n, minus 1.
Remember! If you are calculating standard deviations for a population, this step is a bit different. You should divide by the population size, N, rather than N-1. We use n-1 only when calculating a sample standard deviation in order to get a closer approximation of the population standard deviation.
Step 5. Final Step. Take the square root of the value you found in Step 4.
Voila! The sample standard deviation s = 8.069
A table that lists the steps for calculating standard deviation
Calculating standard deviation using statistical software
While it’s important to understand how to calculate standard deviations by hand, statisticians rarely ever do in practice. Calculating standard deviations by hand can take a lot of time and lead to many errors, especially when dealing with large data sets. Fortunately, it’s incredibly easy to calculate standard deviations using statistical software. Below are some examples of the software and commands you can use.
In Excel or Google sheets, use the formula =STDEV(). The list of your data should be included inside the parentheses. Let’s say your data has ten values in cells A1 through A10; the formula would then be =stdev(A1:A10).
In Desmos, the command for standard deviation is also stdev()
In R and Stata, the command is sd().
For each of these commands, you should include a list of your data or the name of your variable inside the parentheses. For practice, try calculating the standard deviation from the example above using one of the options. See if you get the same answer.
Standard Deviations and Variance
One last thing to note about standard deviations: If you are familiar with variance, you may have noticed that the standard deviation is just the square root of the variance. If you’re not familiar with variance, variance is another measure of spread that is calculated using the following formulas.
Looking at these equations, you may be asking yourself why it’s necessary to have both measures. Why do we calculate standard deviations when we already have variance? The answer to this question lies in the name. The standard deviation is a standardized measure of spread. When calculating the variance, we square the distance between each data point and the mean (xi−μ)2.
We do this so that the distances for values below the mean don’t cancel out distances for the values above the mean. The only problem with doing this is that the squared distances are in units that can’t be interpreted.
Think back to the example we started with: the weight of Tour de France participants. The unit of the data is pounds (lbs). If we square the distance between each cyclist’s weight and the mean weight, we can find the variance using the formula presented above, but the variance is in units that are pounds squared. This makes the variance hard to interpret. When we calculate the standard deviation, we take the square root of the variance to get our measure of spread back into interpretable units, back into pounds rather than pounds squared!
Outlier (from the co-founder of MasterClass) has brought together some of the world's best instructors, game designers, and filmmakers to create the future of online college.