Understanding Sampling Distributions: What Are They and How Do They Work?
10.06.2021 • 12 min read
Sarah Thomas
Subject Matter Expert
Sampling distribution is a key tool in the process of drawing inferences from statistical data sets. Here, we'll take you through how sampling distributions work and explore some common types.
A sampling distribution is the probability distribution of a sample statistic, such as a sample mean (xˉ) or a sample sum (Σx).
Here’s a quick example:
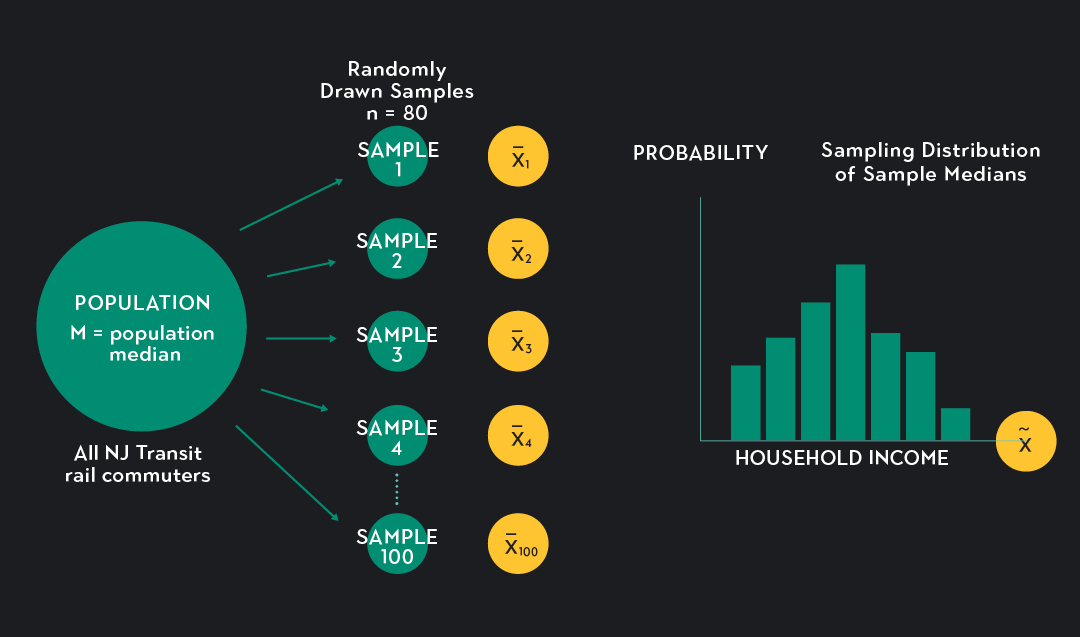
Imagine trying to estimate the mean income of commuters who take the New Jersey Transit rail system into New York City. More than one hundred thousand commuters take these trains each day, so there’s no way you can survey every rider. Instead, you draw a random sample of 80 commuters from this population and ask each person in the sample what their household income is. You find that the mean household income for the sample is xˉ1 = $92,382. This figure is a sample statistic. It’s a number that summarizes your sample data, and you can use it to estimate the population parameter. In this case, the population parameter you are interested in is the mean income of all commuters who use the New Jersey Transit rail system to get to New York City.
Now that you’ve drawn one sample, say you draw 99 more. You now have 100 random samples of sample size n=80, and for each sample, you can calculate a sample mean. We’ll denote these means as xˉ1, xˉ2, … xˉ100, where the subscript indicates the sample for which the mean was calculated. The value of these means will vary. For the first sample, we found a mean income of $92,382, but in another sample, the mean may be higher or lower depending on who gets sampled. In this way, the sample statistic xˉ becomes its own random variable with its own probability distribution. Tallying the values of the sample means and plotting them on a relative frequency histogram gives you the sampling distribution of xˉ(the sampling distribution of the sample mean).
Don’t get confused! The sampling distribution is not the same thing as the probability distribution for the underlying population or the probability distribution of any one of your samples.
In our New Jersey Transit example:
The population distribution is the distribution of household income for all NJ Transit rail commuters.
The sample distribution is the distribution of income for a particular sample of eighty riders randomly drawn from the population.
The sampling distribution is the distribution of the sample statistic xˉ. This is the distribution of the 100 sample means you got from drawing 100 samples.
Why Are Sampling Distributions Important?
Sampling distributions are closely linked to one of the most important tools in statistics: the central limit theorem. There is plenty to say about the central limit theorem, but in short, and for the sake of this article, it tells us two crucial things about properly drawn samples and the shape of sampling distributions:
If you draw a large enough random sample from a population, the distribution of the sampleshould resemble the distribution of the population.
As the number of drawn samples gets larger and larger, and if certain conditions are met, the sampling distributionwill approach a normal distribution.
What conditions need to be met for the central limit theorem to hold?
The central limit theorem applies in situations where the underlying data for the population is normally distributed or in cases where the size of the samples being drawn is greater than or equal to 30 (n≥30). In either case, samples need to be drawn randomly and with replacement.
Here is the magic behind sampling distributions and the central limit theorem. If we know that a sampling distribution is approximately normal, we can use the rules of probability (such as the empirical rule, z-transformations, and more) to make powerful statistical inferences. This is true even if the underlying distribution for the population is not normal or even if the shape of the underlying distribution is unknown. So long as the sample size is equal to or greater than 30, we can use the normal approximation of the sampling distribution to get a better estimate of what the underlying population is like.
A refresher on normal distributions and the empirical rule:
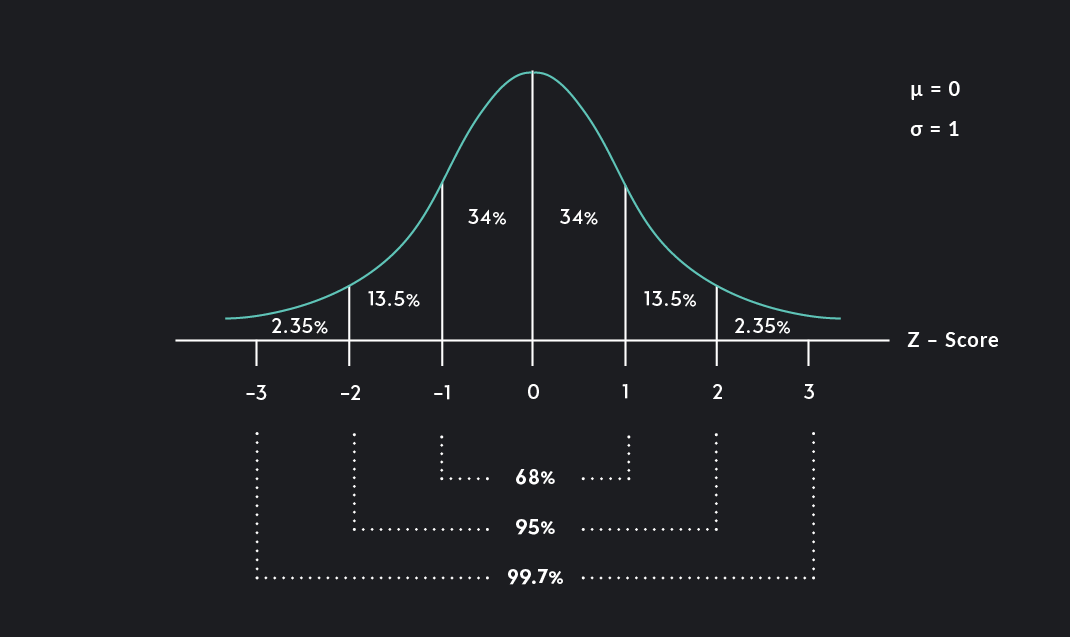
The normal distribution is a bell-shaped distribution that is symmetric around the mean and unimodal.
The empirical ruletells us that 68% of all observations in a normal distribution lie within one standard deviation of the mean, 95% of all observations lie within two standard deviations of the mean, and 99.7% of all observations lie within three standard deviations of the mean.
A refresher on standard normal distributions and z-transformations:
A standard normal distribution is a normal distribution with a mean equal to zero and a standard deviation equal to one.
Any value from a normal distribution can be mapped to a value on the standard normal distribution using a z-transformation.
Z=σ(x−μ)
Types of Sampling Distributions: Means and Sums
Sampling distributions can be constructed for any random-sample-based statistic, so there are many types of sampling distributions. We’ll end this article by briefly exploring the characteristics of two of the most commonly used sampling distributions: the sampling distribution of sample means and the sampling distribution of sample sums.Both of these sampling distributions approach a normal distribution with a particular mean and standard deviation. The standard deviation of a sampling distribution is called the standard error.
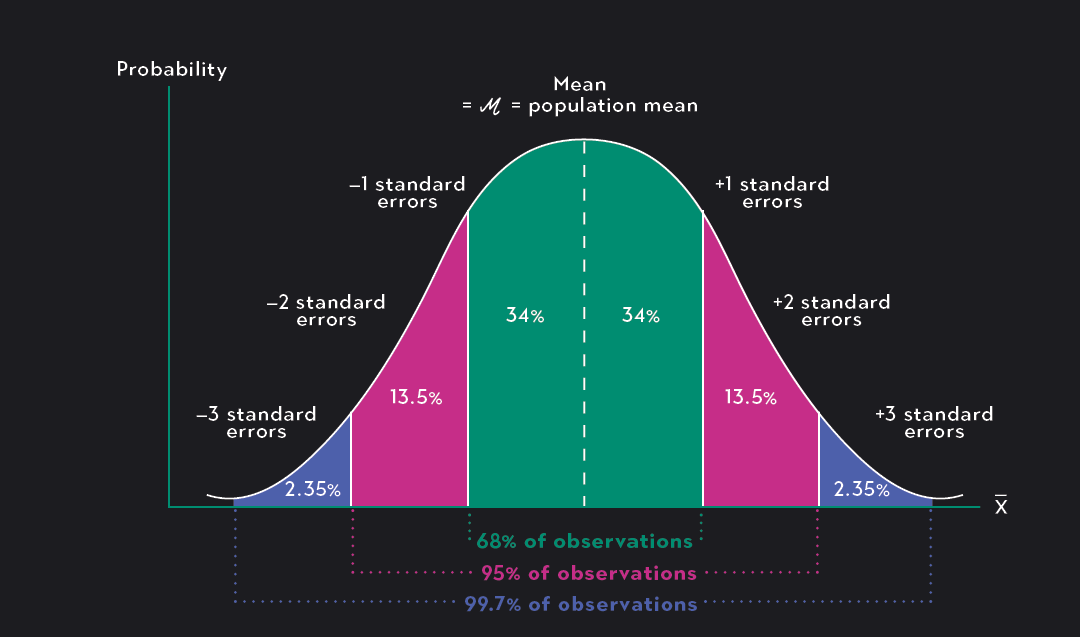
If the central limit theorem holds, the sampling distribution of sample means will approach a normal distribution with a mean equal to the population mean, μ, and a standard error equal to the population standard deviation divided by the square root of the sample size, nσ.
The fact that the distribution of sample means is centered around the population mean is an important one. This means that the expectation of a sample mean is the true population mean, μ, and using the empirical rule, we can assert that if large enough samples of size n are drawn with replacement, 99.7% of the sample means will fall within 3 standard errors of the population mean. Lastly, sampling distribution of means allows you to use z-transformations to make probability statements about the likelihood that a sample mean, xˉ, calculated from a sample of size n, will be between, greater than, or equal to some value(s).
The sampling distribution of sample means:
The sampling distribution of the sample means, xˉ, approaches a normal distribution with mean, μ, and a standard deviation, nσ).
xˉ ~ N(μ, nσ) where μ is the population mean, σ is the population standard deviation, and n is the sample size
Just as the sampling distribution of sample means approaches a normal distribution with a unique mean and standard, so does the sampling distribution of sample sums. A sample sum, Σ, is just the sum of all values in a sample.
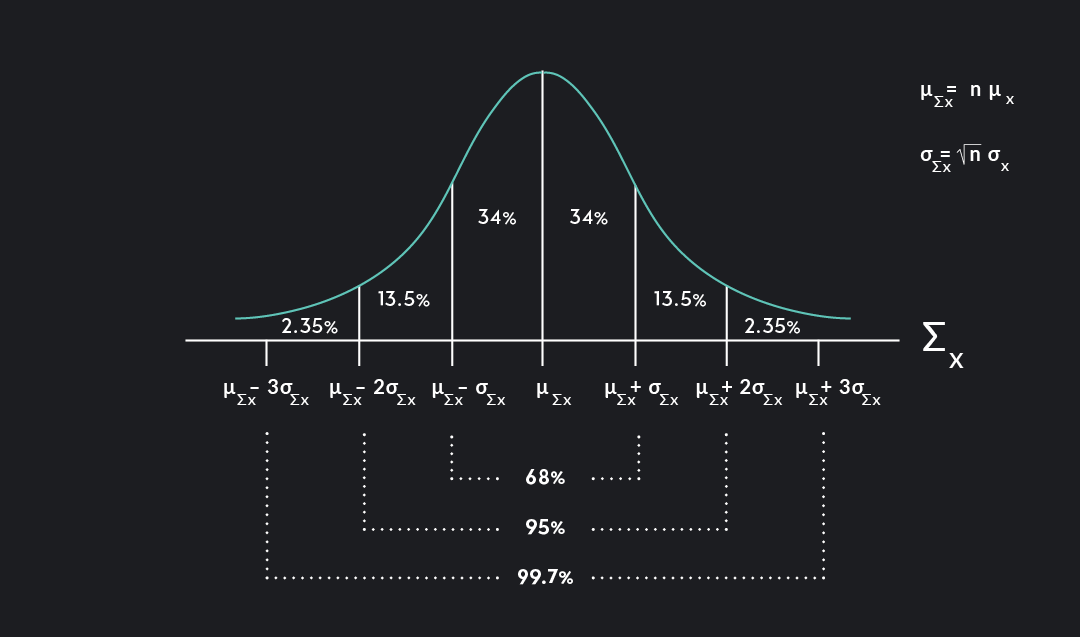
The sampling distribution of sample sums is centered around a mean equal to the sample size multiplied by the population mean, nμ, and the standard error of sums is equal to the square root of the sample size multiplied by the standard deviation of the population: (n)(σ).
The sampling distribution of sample sums:
The sampling distribution of the sample sums, Σ, approaches a normal distribution with mean, nμ, and a standard deviation, (n)(σ).
Σx ~ N(nμx, (n)(σx))
The mean of the sampling distribution of sums μΣx = (n)(μ)
The standard deviation of the sampling distribution of sums σΣx: (n)(σ)
One last reminder:
Remember, the standard error is just a name given to the standard deviation of a sampling distribution.
The standard error of meansis the standard deviation for the sampling distribution of means. It equals nσ when the central limit theorem holds.
The standard error of sumsis the standard deviation of the sampling distribution of sum. It equals (n)(σ) when the central limit theorem holds.
Outlier (from the co-founder of MasterClass) has brought together some of the world's best instructors, game designers, and filmmakers to create the future of online college.